

More Documentation
programming
How To Get Remote IP Address in PHP

most of medium or large projects that companies planning to let their own system to know who’s trying access the project platform or website or any other online services for a security reasons needs to store each connection identity address for each failed attempt user logins to take an temporary action like “Block” or “Secure Accounts”
What’s Flowchart of this program and how it works
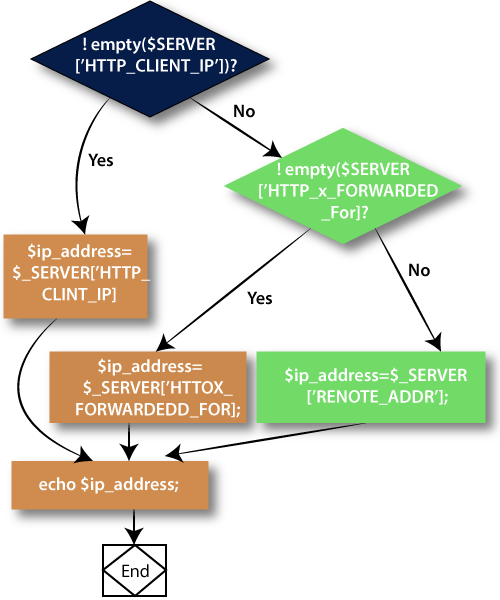
What’s Default Variables and Methods to call these layers
Example 1
$_SERVER is an super global variable containing information such as headers, paths, and script locations.
The entries in this array are created by the web server
‘$_SERVER’ is also like global variable has a couples of methods is responsible to get all network connection header information’s
<?php echo 'User IP Address - '.$_SERVER['REMOTE_ADDR']; ?>
Output
User IP Address - ::1
Things You Need to Know
Always The ‘REMOTE_ADDR’ in localhost does not return the IP address of the client, and the main reason behind is to use the proxy. such as type of situation, we will try another way to get the real IP address of the user in PHP.
if we’ve tried this on localhost environments such as “XAMPP” or “MAMP” or “APPSERV” or any other apache software’s we will get this result and if we’ve tried to upload this code online host and entered the website this will return with the real IP Address so we should test that online
Variable Methods or Indices
‘PHP_SELF ‘
The filename of the currently executing script, relative to the document root
‘GATEWAY_INTERFACE‘
What revision of the CGI specification the server is using
‘SERVER_ADDR’
The IP address of the server under which the current script is executing.
‘SERVER_NAME’
The name of the server host under which the current script is executing. If the script is running on a virtual host, this will be the value defined for that virtual host.
‘SERVER_SOFTWARE’
Server identification string, given in the headers when responding to requests.
‘SERVER_PROTOCOL’
Name and revision of the information protocol via which the page was requested
‘REQUEST_METHOD’
Which request method was used to access the page such as ‘GET‘, ‘HEAD‘, ‘POST‘, ‘PUT‘.
‘REQUEST_TIME‘
The timestamp of the start of the request.
‘REQUEST_TIME_FLOAT’
The timestamp of the start of the request, with microsecond precision.
‘QUERY_STRING’
The query string, if any, via which the page was accessed.
‘DOCUMENT_ROOT‘
The document root directory under which the current script is executing, as defined in the server’s configuration file.
‘HTTP_ACCEPT’
Contents of the Accept: header from the current request, if there is one.
‘HTTP_ACCEPT_CHARSET’
Contents of the Accept-Charset: header from the current request, if there is one. Example: ‘iso-8859-1,*,utf-8‘.
‘HTTP_ACCEPT_ENCODING’
Contents of the Accept-Encoding: header from the current request, if there is one. Example: ‘gzip‘.
‘HTTP_ACCEPT_LANGUAGE’
Contents of the Accept-Language: header from the current request, if there is one. Example: ‘en‘.
‘HTTP_CONNECTION’
Contents of the Connection: header from the current request, if there is one. Example: ‘Keep-Alive‘.
‘HTTP_HOST’
Contents of the Host: header from the current request, if there is one.
‘HTTP_REFERER’
The address of the page if any which referred the user agent to the current page. This is set by the user agent. Not all user agents will set this, and some provide the ability to modify as a feature.
Learn More about indicates of $_SERVER on PHP documentation
Creating The Function
Let’s getting started to create a simple function let us know who’s on remote using getenv function
getenv is built-in function in PHP available for versions (PHP 4, PHP 5, PHP 7, PHP 8)
<?php
function get_client_ip() {
$ipaddress = '';
if (getenv('HTTP_CLIENT_IP'))
$ipaddress = getenv('HTTP_CLIENT_IP');
else if(getenv('HTTP_X_FORWARDED_FOR'))
$ipaddress = getenv('HTTP_X_FORWARDED_FOR');
else if(getenv('HTTP_X_FORWARDED'))
$ipaddress = getenv('HTTP_X_FORWARDED');
else if(getenv('HTTP_FORWARDED_FOR'))
$ipaddress = getenv('HTTP_FORWARDED_FOR');
else if(getenv('HTTP_FORWARDED'))
$ipaddress = getenv('HTTP_FORWARDED');
else if(getenv('REMOTE_ADDR'))
$ipaddress = getenv('REMOTE_ADDR');
else
$ipaddress = 'UNKNOWN';
return $ipaddress;
}
?>
Excuting Function
<?php echo get_client_ip(); ?>
Documentations
getenv
$_SERVER

The var_dump function displays structured information about variables/expressions including its type and value. Arrays are explored recursively with values indented to show structure. It also shows which array values and object properties are references.
The print_r() displays information about a variable in a way that’s readable by humans. array values will be presented in a format that shows keys and elements. Similar notation is used for objects.
Example:
$obj = (object) array('qualitypoint', 'technologies', 'egypt');
var_dump($obj) will display below output in the screen.
object(stdClass)#1 (3) {
[0]=> string(12) "qualitypoint"
[1]=> string(12) "technologies"
[2]=> string(5) "egypt"
}
And, print_r($obj) will display below output in the screen.
stdClass Object ( [0] => qualitypoint [1] => technologies [2] => egypt )

There are various reasons for tracking what an user does:
- Keeping track of the refering page for forms, so they can be sent back to where they came from
- Tracking usage behavior for statistics
- etc.
Let’s look at how we could implement a simple user tracker in PHP with Zend Framework. I’m going to write a bit of the theory too, so this might help you even if you’re not using ZF.
The basic idea
As we know, the browser keeps a history of visited pages. However, we can’t access this at all, with the exception of some older version of IE (I think), so we must think of some other way to do it.
The browser usually lets the server see the exact previous page where it came from: the referer URL.
There’s just one problem: it isn’t always populated. Some firewalls can optionally block it, some browsers have an option to turn it off etc., so it can’t be used very reliably.
This is why we need a custom method for tracking urls. Of course, this will only work on our site, but that doesn’t matter – we don’t want to literally spy on our users, now do we?
Since we can see each request the user does to our site, we can employ a simple strategy: Every time the user opens a page, store the opened page’s URL in an array in the session. This way we can collect the browsing history on our page.
The implementation
We could implement this in Zend Framework as a front controller plugin and it would get automatically executed on every request, but it has a limitation. Since it would probaby be nice to be able to access the history, for example to redirect the user back to a page, we can’t go with the front controller plugin.
The best option would probably be a action helper. Just like front controller plugins, they can get automatically executed on every request, but they can also be accessed from the controller actions, making it possible to use the history data easily.
In case you haven’t heard about action helpers, check the action helpers chapter of Zend Framework manual. It will help you understand what the code we’ll be writing soon does.
The code
The class should be rather obvious for the most part. Most of the things happen in _initSession and preDispatch, which handle the tracking.
private function _initSession()
{
$this->_namespace = new Zend_Session_Namespace('CU_Controller_Action_Helper_History');
if(!is_array($this->_namespace->history))
{
$this->_namespace->history = array();
if(!empty($_SERVER['HTTP_REFERER']))
array_unshift($this->_namespace->history, $_SERVER['HTTP_REFERER']);
}
else
array_splice($this->_namespace->history, $this->_trackAmount);
}
Despite being the biggest method of the class, _initSession is rather simple. It opens a session namespace and sees if there was previous data for the history or not. In case there was nothing in, it also checks the HTTP_REFERER header; this allows us to see at least the refering site where they came from. If there was some data in, it uses array_splice to cut the length of the history to the max limit.
preDispatch simply uses the Url helper to get the current URL and uses array_unshift to make it the 0th index in the array. Rest of the class should be quite obvious.
As can be seen, the history logic works quite simply. Each URL is kept in an array in the session in a namespace so there will be no collisions. The current page is the 0th, the previous is 1st, the one before that 2nd and so on. The default amount of URLs to track is two because that should be enough for the typical scenario of form redirection: You go to a page which links to the form, which you submit, making the initial page the 2nd in history.
Using the class
Using the class is very simple. First, we must add the helper to the HelperBroker, for example in our bootstrap:
Zend_Controller_Action_HelperBroker::addHelper(new CU_Controller_Action_Helper_History());
This is so that the helper gets initialized and will be notified on each request. If we used addPath, the helper would not get initialized before it’s used in a controller, effectively missing preDispatch.
Now, we can use this in our controller:
We can also use getPreviousUrl or getArray to get the visited URLs without redirecting.
public function someAction()
{
$this->_helper->history->goBack(2); //jump back two pages in history
}
Conclusion
This is a pretty useful feature in my opinion. I often need this kind of things with my forms and so far I’ve actually rewritten the same redirection code again and again.
This could also be expanded from here to track more specific actions, perhaps even how long the user spent between requests. That way it could be used for creating statistics of user behavior on the site, such as navigation paths and other things.

At the scale that Facebook operates, several traditional approaches to serving web content break down or simply aren’t practical.
The challenge for Facebook’s engineers has been to keep the site up and running smoothly in spite of handling over two billion active users. This article takes a look at some of the software and techniques they use to accomplish that.
Facebook’s Scaling Challenge
Before we get into the details, here are a few factoids to give you an idea of the scaling challenge that Facebook has to deal with:
- Facebook had 2.3 billion users as of Q4 2018 (the service is available in over 100 languages)
- Every 60 seconds: 317 thousand status updates are added, 147 thousand photos are uploaded, and 54 thousand links are shared on Facebook
- Facebook users generate 8 billion video views per day on average, 20% of which are live broadcast
- In 2018, Facebook had 15 million square feet of data center space among its 15 campuses around the globe that host millions of servers
Check out this blog post to learn more stats on the most used social media platforms.
Software That Helps Facebook Scale
In some ways Facebook is still a LAMP site (kind of) which refers to services using Linux, Apache, MySQL, and PHP, but it has had to change and extend its operation to incorporate a lot of other elements and services, and modify the approach to existing ones.
For example:
- Facebook still uses PHP, but it has built a compiler for it so it can be turned into native code on its web servers, thus boosting performance.
- Facebook uses Linux, but has optimized it for its own purposes (especially in terms of network throughput).
- Facebook uses MySQL, but primarily as a key-value persistent storage, moving joins and logic onto the web servers since optimizations are easier to perform there (on the “other side” of the Memcached layer).
Then there are the custom-written systems, like Haystack, a highly scalable object store used to serve Facebook’s immense amount of photos, or Scribe, a logging system that can operate at Facebook’s scale (which is far from trivial).
But enough of that. Let’s present (some of) the software that Facebook uses to provide us all with the world’s largest social network site.
Memcached
 Memcached is by now one of the most famous pieces of software on the internet. It’s a distributed memory caching system which Facebook (and a ton of other sites) use as a caching layer between the web servers and MySQL servers (since database access is relatively slow). Through the years, Facebook has made a ton of optimizations to Memcached and the surrounding software (like optimizing the network stack).
Memcached is by now one of the most famous pieces of software on the internet. It’s a distributed memory caching system which Facebook (and a ton of other sites) use as a caching layer between the web servers and MySQL servers (since database access is relatively slow). Through the years, Facebook has made a ton of optimizations to Memcached and the surrounding software (like optimizing the network stack).
Facebook runs thousands of Memcached servers with tens of terabytes of cached data at any one point in time. It is likely the world’s largest Memcached installation.
HipHop for PHP and HipHop Virtual Machine (HHVM)
 PHP, being a scripting language, is relatively slow when compared to code that runs natively on a server. HipHop converts PHP into C++ code which can then be compiled for better performance. This has allowed Facebook to get much more out of its web servers since Facebook relies heavily on PHP to serve content.
PHP, being a scripting language, is relatively slow when compared to code that runs natively on a server. HipHop converts PHP into C++ code which can then be compiled for better performance. This has allowed Facebook to get much more out of its web servers since Facebook relies heavily on PHP to serve content.
A small team of engineers (initially just three of them) at Facebook spent 18 months developing HipHop, and it was used for a few years. The project was discontinued back in 2013 and then replaced by HHVM (HipHop Virtual Machine).
Haystack
Haystack is Facebook’s high-performance photo storage/retrieval system (strictly speaking, Haystack is an object store, so it doesn’t necessarily have to store photos). It has a ton of work to do; there are more than 20 billion uploaded photos on Facebook, and each one is saved in four different resolutions, resulting in more than 80 billion photos.
And it’s not just about being able to handle billions of photos; web performance is critical. As we mentioned previously, Facebook users upload around 147,000 photos every minute which makes it 2,450 photos per second.
BigPipe
BigPipe is a dynamic web page serving system that Facebook has developed. Facebook uses it to serve each web page in sections (called “pagelets”) for optimal performance.
For example, the chat window is retrieved separately, the news feed is retrieved separately, and so on. These pagelets can be retrieved in parallel, which is where the performance gain comes in, and it also gives users a site that works even if some part of it would be deactivated or broken.
Cassandra (Instagram)
![]() Cassandra is a distributed storage system with no single point of failure. It’s one of the poster children for the NoSQL movement and has been made open source (it’s even become an Apache project). Facebook used it for its Inbox search.
Cassandra is a distributed storage system with no single point of failure. It’s one of the poster children for the NoSQL movement and has been made open source (it’s even become an Apache project). Facebook used it for its Inbox search.
Other than Facebook, a number of other services use it, for example Digg. We’re even considering some uses for it here at SolarWinds® Pingdom®.
Facebook abandoned Cassandra back in 2010 but the solution has been used at Instagram since 2012 replacing Redis.
Scribe
Scribe was a flexible logging system that Facebook used for a multitude of purposes internally. It’s been built to be able to handle logging at the scale of Facebook, and automatically handles new logging categories as they show up (Facebook has hundreds). As of 2019, Scribe’s GitHub repository states that this project is no longer supported or updated by Facebook which probably means that it’s not in use anymore.
Hadoop and Hive
![]() Hadoop is an open source map-reduce implementation that makes it possible to perform calculations on massive amounts of data. Facebook uses this for data analysis (and as we all know, Facebook has massive amounts of data). Hive originated from within Facebook, and makes it possible to use SQL queries against Hadoop, making it easier for non-programmers to use.
Hadoop is an open source map-reduce implementation that makes it possible to perform calculations on massive amounts of data. Facebook uses this for data analysis (and as we all know, Facebook has massive amounts of data). Hive originated from within Facebook, and makes it possible to use SQL queries against Hadoop, making it easier for non-programmers to use.
Both Hadoop and Hive are open source (Apache projects) and are used by a number of big services, for example Yahoo and Twitter.
For more information, check out the article on “How Is Facebook Deploying Big Data?”
Thrift
Facebook uses several different languages for its different services. PHP is used for the front-end, Erlang is used for Chat, Java and C++ are also used in several places (and perhaps other languages as well). Thrift is an internally developed cross-language framework that ties all of these different languages together, making it possible for them to talk to each other. This has made it much easier for Facebook to keep up its cross-language development.
Facebook has made Thrift open source and support for even more languages has been added.
Varnish
 Varnish is an HTTP accelerator which can act as a load balancer and also cache content which can then be served lightning-fast.
Varnish is an HTTP accelerator which can act as a load balancer and also cache content which can then be served lightning-fast.
Facebook uses Varnish to serve photos and profile pictures, handling billions of requests every day. Like almost everything Facebook uses, Varnish is open source.
React
![]() React is an open-source JavaScript library created in 2011 by Jordan Walke, a software engineer at Facebook. Later, Facebook introduced React Fiber, which is a collection of algorithms for rendering graphics. Interestingly, React is now one of the world’s most widely used JavaScript libraries. Read the story of how React became so successful.
React is an open-source JavaScript library created in 2011 by Jordan Walke, a software engineer at Facebook. Later, Facebook introduced React Fiber, which is a collection of algorithms for rendering graphics. Interestingly, React is now one of the world’s most widely used JavaScript libraries. Read the story of how React became so successful.
Other Things That Help Facebook Run Smoothly
We have mentioned some of the software that makes up Facebook’s system(s) and helps the service scale properly. But handling such a large system is a complex task, so we thought we would list a few more things that Facebook does to keep its service running smoothly.
Gradual Releases and Dark Launches
Facebook has a system they called Gatekeeper that lets them run different code for different sets of users (it basically introduces different conditions in the code base). This lets Facebook do gradual releases of new features, A/B testing, activate certain features only for Facebook employees, etc.
Gatekeeper also lets Facebook do something called “dark launches”, which are to activate elements of a certain feature behind the scenes before it goes live (without users noticing since there will be no corresponding UI elements). This acts as a real-world stress test and helps expose bottlenecks and other problem areas before a feature is officially launched. Dark launches are usually done two weeks before the actual launch.
Profiling of the Live System
Facebook carefully monitors its systems (something we here at Pingdom of course approve of), and interestingly enough it also monitors the performance of every single PHP function in the live production environment. This profiling of the live PHP environment is done using an open source tool called XHProf.
Gradual Feature Disabling for Added Performance
If Facebook runs into performance issues, there are a large number of levers that let them gradually disable less important features to boost performance of Facebook’s core features.
The Things We Didn’t Mention
We didn’t go much into the hardware side in this article, but of course that is also an important aspect when it comes to scalability. For example, like many other big sites, Facebook uses a CDN to help serve static content. And then of course there are many data centers Facebook has, including the 27,000-square meter facility in Lulea, Sweden, launched in 2013. One of the latest data center projects is the massive 11-story, 170,000-square-meter building the company has announced to open in Singapore by 2022.
And aside from what we have already mentioned, there is of course a ton of other software involved. However, we hope we were able to highlight some of the more interesting choices Facebook has made.
Facebook’s Love Affair with Open Source
We can’t complete this article without mentioning how much Facebook likes open source. Or perhaps we should say, “loves”.
Not only is Facebook using (and contributing to) open source software such as Linux, Memcached, MySQL, Hadoop, and many others, it has also made much of its internally developed software available as open source.
Examples of open-source projects that originated from inside Facebook include HipHop, Cassandra, Thrift, and Scribe. Facebook has also open-sourced Tornado, a high-performance web server framework developed by the team behind FriendFeed (which Facebook bought in August 2009).
(A list of open-source software that Facebook is involved with can be found on Facebook’s Open Source page.)
More Scaling Challenges to Come
Facebook has been growing at an incredible pace. Its user base is increasing almost exponentially and now includes over two billion active users—and who knows what it will be by the end of the year.
Facebook even has a dedicated “growth team” that constantly tries to figure out how to make people use and interact with the site even more.
This rapid growth means that Facebook will keep running into various performance bottlenecks as it’s challenged by more and more page views, searches, uploaded images (including images formats and sizes), status messages, and all the other ways that Facebook users interact with the site and each other.
But this is just a fact of life for a service like Facebook. Facebook’s engineers will keep iterating and coming up with new ways to scale (it’s not just about adding more servers). For example, Facebook’s photo storage system has already been completely rewritten several times as the site has grown.
So, we’ll see what the engineers at Facebook come up with next. We bet it’s something interesting. After all, they are scaling a mountain that most of us can only dream of; a site with more users than most countries. When you do that, you better get creative.
If you’re interested in how the Internet works, be sure to check out our article on how Google collects data about you and the Internet.
Data sources: Various presentations by Facebook engineers, as well as the always informative Facebook engineering blog.
News9 months ago
Microsoft’s ‘Blue Screen of Death’ returns

News9 months ago
Fired SpaceX employees sue the company
Social Media9 months ago
Verified blue tick X’s accounts deceive users

-
 Engineering4 years ago
Engineering4 years agoFacebook Database Architecture Design Review
-
 Social Media4 years ago
Social Media4 years agoComplete Guide For Contact Facebook Directly
-
programming4 years ago
How to tracking user browser activities using PHP Programming
-
 Social Media4 years ago
Social Media4 years agoTwitter let accounts to request a verification badge
-
 Facebook4 years ago
Facebook4 years agoBecome Facebook Agency Partner
-
 Twitter4 years ago
Twitter4 years agoHow to request blue badge on twitter
-
 Social Media4 years ago
Social Media4 years agoFacebook Audience Insights No Longer Available
-
 Microsoft4 years ago
Microsoft4 years agoIntroducing Microsoft Windows 11 What’s New Features